
The early_stopping parameter in scikit-learn’s MLPClassifier determines whether to use early stopping to prevent overfitting during training.
Multi-layer Perceptron (MLP) is a type of artificial neural network used for classification tasks. The early_stopping parameter enables the model to stop training when validation performance stops improving.
Early stopping helps prevent overfitting by monitoring the model’s performance on a validation set during training. If the performance doesn’t improve for a specified number of iterations, training stops.
The default value for early_stopping is False.
When enabled, a common practice is to set early_stopping=True and adjust the validation_fraction and n_iter_no_change parameters to fine-tune the early stopping behavior.
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# Generate synthetic dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=10,
n_redundant=5, n_classes=3, random_state=42)
# Split into train, validation, and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
# Train with and without early stopping
mlp_no_early = MLPClassifier(hidden_layer_sizes=(100, 50), max_iter=500, random_state=42)
mlp_early = MLPClassifier(hidden_layer_sizes=(100, 50), max_iter=500, random_state=42,
early_stopping=True, validation_fraction=0.2, n_iter_no_change=10)
mlp_no_early.fit(X_train, y_train)
mlp_early.fit(X_train, y_train)
# Evaluate models
print(f"No early stopping - Accuracy: {accuracy_score(y_test, mlp_no_early.predict(X_test)):.3f}")
print(f"With early stopping - Accuracy: {accuracy_score(y_test, mlp_early.predict(X_test)):.3f}")
# Plot learning curves
plt.figure(figsize=(10, 5))
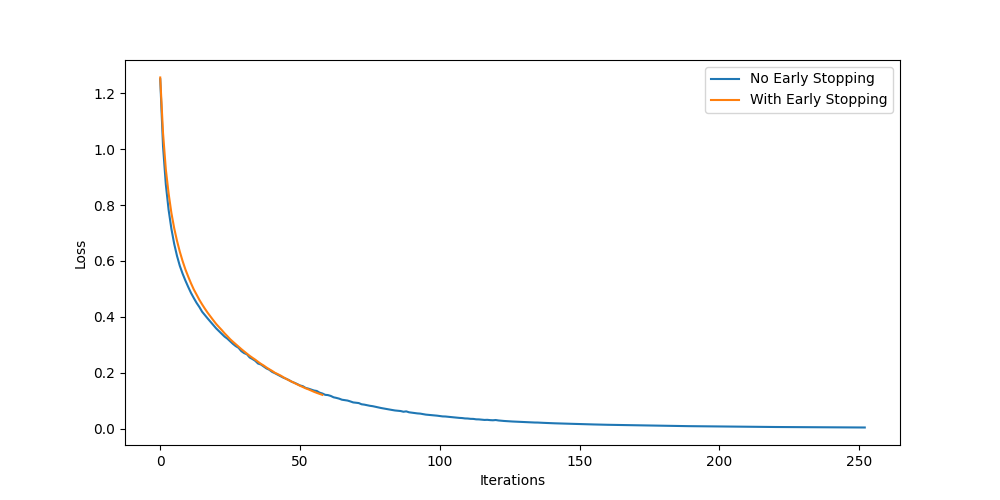
plt.plot(mlp_no_early.loss_curve_, label='No Early Stopping')
plt.plot(mlp_early.loss_curve_, label='With Early Stopping')
plt.xlabel('Iterations')
plt.ylabel('Loss')
plt.legend()
plt.show()
Running the example gives an output like:
No early stopping - Accuracy: 0.880
With early stopping - Accuracy: 0.850
The key steps in this example are:
- Generate a synthetic multi-class classification dataset
- Split the data into train, validation, and test sets
- Create two
MLPClassifierinstances, one with early stopping and one without - Train both models and compare their accuracy on the test set
- Plot learning curves to visualize the effect of early stopping
Some tips and heuristics for using early stopping:
- Use early stopping when you have a large dataset or complex model architecture
- Adjust
validation_fractionto control the size of the validation set - Tune
n_iter_no_changeto balance between stopping too early and too late - Monitor both training and validation loss to detect overfitting
Issues to consider:
- Early stopping may prevent the model from reaching its full potential on some datasets
- The effectiveness of early stopping depends on the quality of the validation set
- Early stopping increases computation time due to frequent validation checks
- The optimal early stopping parameters may vary depending on the specific problem and dataset