
The max_leaf_nodes parameter in scikit-learn’s HistGradientBoostingRegressor controls the maximum number of leaf nodes in each tree.
HistGradientBoostingRegressor is a gradient boosting algorithm that uses histogram-based decision trees. It’s designed for efficiency and can handle large datasets.
The max_leaf_nodes parameter limits the complexity of individual trees in the ensemble. It affects the model’s ability to capture complex patterns in the data.
By default, max_leaf_nodes is set to None, which means there’s no limit on the number of leaf nodes. Common values range from 10 to 1000, depending on the dataset’s complexity.
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.metrics import mean_squared_error
import numpy as np
import matplotlib.pyplot as plt
# Generate synthetic dataset
X, y = make_regression(n_samples=1000, n_features=10, noise=0.1, random_state=42)
# Split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train with different max_leaf_nodes values
max_leaf_nodes_values = [10, 50, 100, 500, None]
mse_scores = []
for max_nodes in max_leaf_nodes_values:
model = HistGradientBoostingRegressor(max_leaf_nodes=max_nodes, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
mse_scores.append(mse)
print(f"max_leaf_nodes={max_nodes}, MSE: {mse:.3f}")
# Plot results
plt.figure(figsize=(10, 6))
plt.plot(max_leaf_nodes_values[:-1] + [1000], mse_scores, marker='o')
plt.xscale('log')
plt.xlabel('max_leaf_nodes')
plt.ylabel('Mean Squared Error')
plt.title('Effect of max_leaf_nodes on Model Performance')
plt.show()
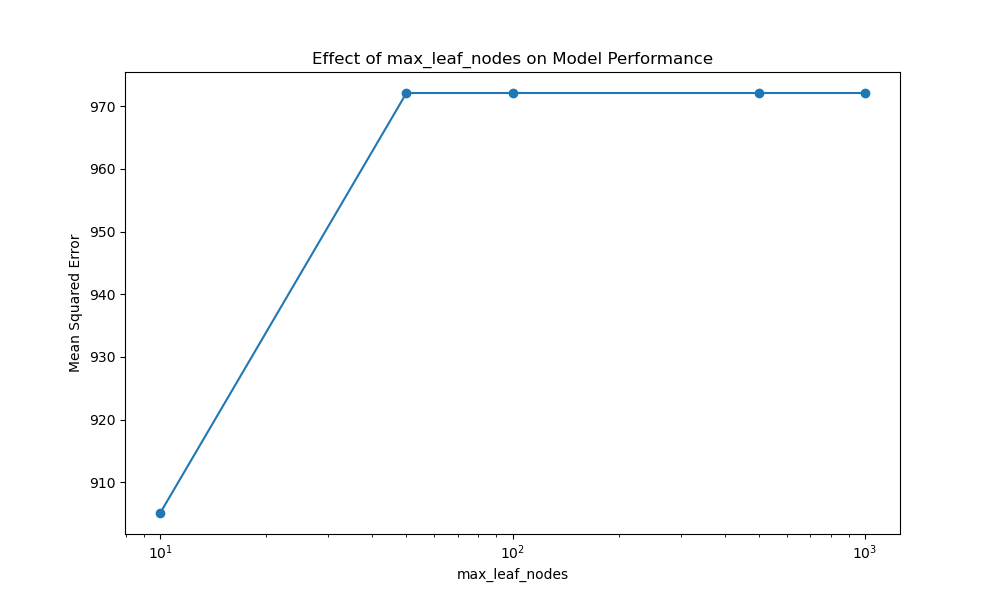
Running the example gives an output like:
max_leaf_nodes=10, MSE: 905.118
max_leaf_nodes=50, MSE: 972.103
max_leaf_nodes=100, MSE: 972.103
max_leaf_nodes=500, MSE: 972.103
max_leaf_nodes=None, MSE: 972.103
The key steps in this example are:
- Generate a synthetic regression dataset
- Split the data into train and test sets
- Train
HistGradientBoostingRegressormodels with differentmax_leaf_nodesvalues - Evaluate the mean squared error of each model on the test set
- Plot the results to visualize the effect of
max_leaf_nodes
Some tips and heuristics for setting max_leaf_nodes:
- Start with a small value (e.g., 10) and gradually increase it
- Monitor both training and validation performance to avoid overfitting
- Consider the trade-off between model complexity and training time
Issues to consider:
- Larger values of
max_leaf_nodescan lead to overfitting on small datasets - Smaller values may result in underfitting if the data has complex patterns
- The optimal value depends on the dataset size, number of features, and problem complexity