
The max_iter parameter in scikit-learn’s HistGradientBoostingRegressor controls the maximum number of iterations during model training.
HistGradientBoostingRegressor is a gradient boosting algorithm that uses histogram-based decision trees. It builds an ensemble of weak learners sequentially, with each new tree correcting errors made by the previous ones.
The max_iter parameter determines the maximum number of boosting stages to perform. It directly affects the model’s complexity and training time. Higher values allow the model to capture more complex patterns but may lead to overfitting.
The default value for max_iter is 100.
In practice, values between 50 and 1000 are commonly used, depending on the dataset’s complexity and size.
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.metrics import mean_squared_error
import numpy as np
import matplotlib.pyplot as plt
# Generate synthetic dataset
X, y = make_regression(n_samples=1000, n_features=10, noise=0.1, random_state=42)
# Split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train with different max_iter values
max_iter_values = [10, 50, 100, 500, 1000]
mse_scores = []
for iter_value in max_iter_values:
model = HistGradientBoostingRegressor(max_iter=iter_value, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
mse_scores.append(mse)
print(f"max_iter={iter_value}, MSE: {mse:.4f}")
# Plot learning curve
plt.plot(max_iter_values, mse_scores, marker='o')
plt.xlabel('max_iter')
plt.ylabel('Mean Squared Error')
plt.title('Effect of max_iter on Model Performance')
plt.xscale('log')
plt.show()
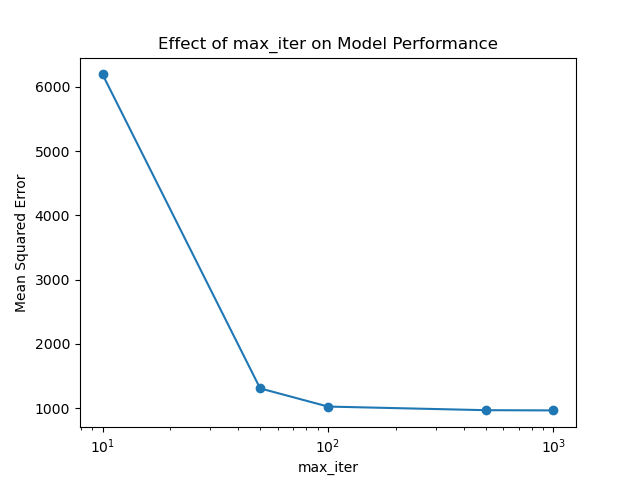
Running the example gives an output like:
max_iter=10, MSE: 6192.5739
max_iter=50, MSE: 1306.1602
max_iter=100, MSE: 1023.0742
max_iter=500, MSE: 966.7014
max_iter=1000, MSE: 963.4431
The key steps in this example are:
- Generate a synthetic regression dataset
- Split the data into train and test sets
- Train
HistGradientBoostingRegressormodels with differentmax_itervalues - Evaluate the mean squared error of each model on the test set
- Visualize the effect of
max_iteron model performance
Some tips and heuristics for setting max_iter:
- Start with the default value of 100 and adjust based on model performance
- Increase
max_iterif the model is underfitting or decrease if overfitting - Monitor validation performance to find the optimal number of iterations
- Consider using early stopping to automatically determine the optimal number of iterations
Issues to consider:
- Higher
max_itervalues increase training time and computational resources required - Very high
max_itervalues may lead to overfitting, especially on small datasets - The optimal
max_iterdepends on the complexity of the problem and the dataset size - Balance between model performance and training time when selecting
max_iter