
The monotonic_cst parameter in scikit-learn’s HistGradientBoostingClassifier allows you to enforce monotonic constraints on the relationship between features and the target variable.
Monotonic constraints ensure that the predicted probability (or score) always increases (or decreases) as a feature value increases, regardless of the values of other features. This can be useful when you have domain knowledge about the expected relationship between features and the target.
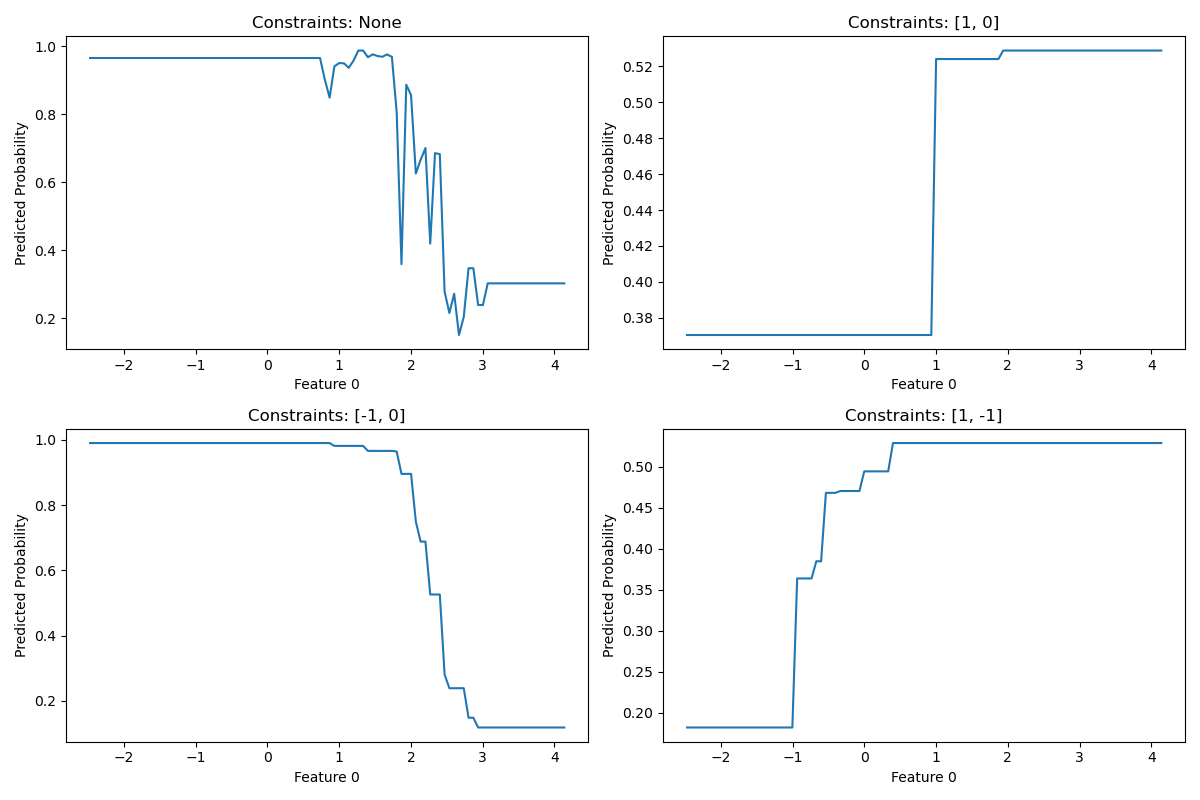
The monotonic_cst parameter accepts a list or dictionary specifying the constraint for each feature. Use -1 for a decreasing relationship, 1 for an increasing relationship, and 0 for no constraint.
By default, monotonic_cst is set to None, which means no monotonicity constraints are applied.
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# Generate synthetic dataset
X, y = make_classification(n_samples=1000, n_features=2, n_informative=2,
n_redundant=0, n_clusters_per_class=1, random_state=42)
# Split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train models with different monotonic constraints
constraints = [None, [1, 0], [-1, 0], [1, -1]]
models = []
for cst in constraints:
model = HistGradientBoostingClassifier(monotonic_cst=cst, random_state=42)
model.fit(X_train, y_train)
models.append(model)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Constraints: {cst}, Accuracy: {accuracy:.3f}")
# Visualize the effect of monotonic constraints
x_plot = np.linspace(X[:, 0].min(), X[:, 0].max(), 100).reshape(-1, 1)
x_plot = np.hstack([x_plot, np.zeros_like(x_plot)])
plt.figure(figsize=(12, 8))
for i, (model, cst) in enumerate(zip(models, constraints)):
y_plot = model.predict_proba(x_plot)[:, 1]
plt.subplot(2, 2, i+1)
plt.plot(x_plot[:, 0], y_plot)
plt.title(f"Constraints: {cst}")
plt.xlabel("Feature 0")
plt.ylabel("Predicted Probability")
plt.tight_layout()
plt.show()
Running the example gives an output like:
Constraints: None, Accuracy: 0.925
Constraints: [1, 0], Accuracy: 0.930
Constraints: [-1, 0], Accuracy: 0.930
Constraints: [1, -1], Accuracy: 0.520
The key steps in this example are:
- Generate a synthetic binary classification dataset with two features
- Split the data into train and test sets
- Train
HistGradientBoostingClassifiermodels with differentmonotonic_cstconfigurations - Evaluate the accuracy of each model on the test set
- Visualize the effect of monotonic constraints on the relationship between feature 0 and the predicted probability
Some tips for setting monotonic_cst:
- Use domain knowledge to determine appropriate constraints for each feature
- Consider the trade-off between model flexibility and enforcing business rules or expected relationships
- Start with no constraints and gradually add them as needed, monitoring the impact on model performance
Issues to consider:
- Enforcing monotonicity constraints may reduce model flexibility and potentially impact performance
- Constraints can help prevent overfitting in some cases, but may lead to underfitting if too restrictive
- The computational cost of training increases when monotonicity constraints are applied