
The ccp_alpha parameter in scikit-learn’s ExtraTreesClassifier controls the complexity of the trees through cost-complexity pruning.
Extra Trees (Extremely Randomized Trees) is an ensemble method similar to Random Forests but with additional randomization in the tree-building process. It creates multiple decision trees and aggregates their predictions.
Cost-complexity pruning is a technique to reduce the complexity of decision trees by pruning branches that provide little improvement in error reduction compared to their complexity cost. The ccp_alpha parameter sets the threshold for this pruning.
The default value for ccp_alpha is 0.0, which means no pruning is performed. Typical values range from 0.0 to 0.1, with smaller values allowing more complex trees and larger values encouraging simpler trees.
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.metrics import accuracy_score
# Generate synthetic dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=10,
n_redundant=5, n_classes=2, random_state=42)
# Split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train with different ccp_alpha values
ccp_alpha_values = [0.0, 0.01, 0.05, 0.1]
accuracies = []
for alpha in ccp_alpha_values:
et = ExtraTreesClassifier(n_estimators=100, ccp_alpha=alpha, random_state=42)
et.fit(X_train, y_train)
y_pred = et.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
accuracies.append(accuracy)
print(f"ccp_alpha={alpha}, Accuracy: {accuracy:.3f}")
# Plot results
import matplotlib.pyplot as plt
plt.plot(ccp_alpha_values, accuracies, marker='o')
plt.xlabel('ccp_alpha')
plt.ylabel('Accuracy')
plt.title('Effect of ccp_alpha on ExtraTreesClassifier Accuracy')
plt.show()
Running the example gives an output like:
ccp_alpha=0.0, Accuracy: 0.925
ccp_alpha=0.01, Accuracy: 0.835
ccp_alpha=0.05, Accuracy: 0.650
ccp_alpha=0.1, Accuracy: 0.490
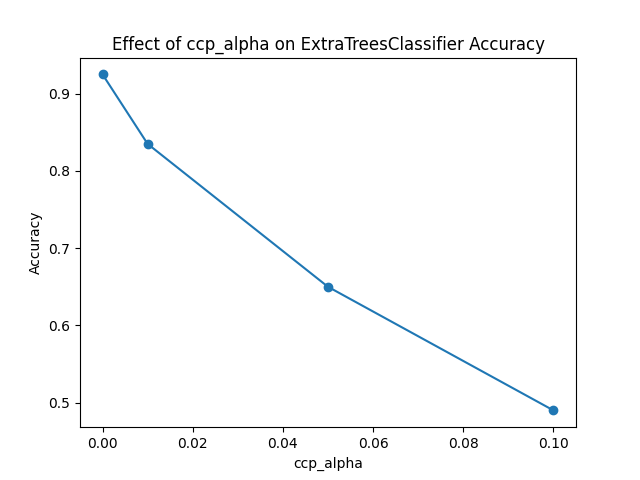
The key steps in this example are:
- Generate a synthetic binary classification dataset with informative and noise features
- Split the data into train and test sets
- Train
ExtraTreesClassifiermodels with differentccp_alphavalues - Evaluate the accuracy of each model on the test set
- Visualize the relationship between
ccp_alphaand model accuracy
Tips and heuristics for setting ccp_alpha:
- Start with the default value of 0.0 and gradually increase it
- Use cross-validation to find the optimal
ccp_alphafor your specific dataset - Consider the trade-off between model complexity and performance
- Larger
ccp_alphavalues lead to simpler trees, which may generalize better on noisy data
Issues to consider:
- The optimal
ccp_alphadepends on the characteristics of your dataset - Very large
ccp_alphavalues may lead to underfitting - The effect of
ccp_alphamay vary depending on other hyperparameters likemax_depth - Pruning with
ccp_alphacan help reduce overfitting and improve model interpretability