
KMeans clustering is an unsupervised learning algorithm used to partition data into distinct clusters based on feature similarity.
The key hyperparameters of KMeans include the number of clusters (n_clusters), the method for initialization (init), the number of initializations (n_init), and the maximum number of iterations (max_iter).
The algorithm is suitable for clustering tasks in unsupervised learning.
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# generate synthetic dataset
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# create KMeans model
model = KMeans(n_clusters=4, init='k-means++', n_init=10, max_iter=300, random_state=0)
# fit the model
model.fit(X)
# predict the cluster for each sample
y_kmeans = model.predict(X)
# visualize the clusters
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
# plot the centroids
centers = model.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75, marker='X')
plt.show()
# make a prediction for a new sample
new_sample = [[0, 0]]
cluster = model.predict(new_sample)
print('Cluster:', cluster[0])
Running the example gives an output like:
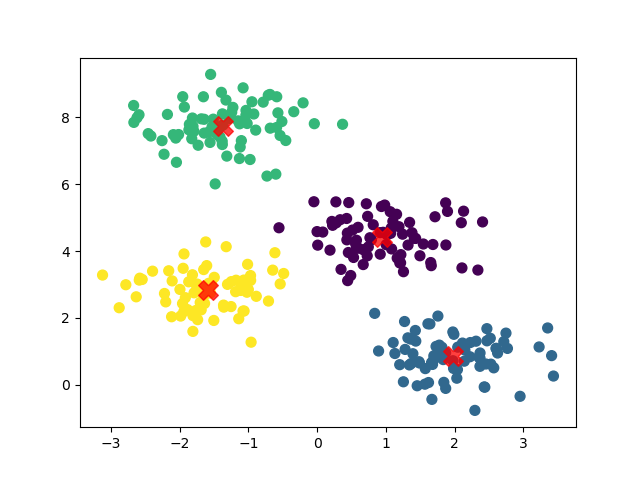
The steps are as follows:
Generate a synthetic dataset using the
make_blobs()function. This creates a dataset with a specified number of samples (n_samples), clusters (centers), and a fixed random seed (random_state) for reproducibility.Instantiate a
KMeansmodel withn_clustersset to 4 and other hyperparameters (init,n_init,max_iter) set to their typical values. The model is then fit on the dataset using thefit()method.Predict the cluster assignments for the dataset using the
predict()method. This assigns each data point to one of the clusters.Visualize the clusters and centroids using
matplotlib. The scatter plot shows how the data points are grouped into clusters and highlights the centroids of each cluster.Make a prediction for a new sample point by passing it to the
predict()method. The output indicates which cluster the new sample belongs to.
This example demonstrates how to set up and use a KMeans model for clustering tasks, showcasing its effectiveness in grouping similar data points into distinct clusters.